
The Gemini API code execution feature enables the model to generate and run Python code and learn iteratively from the results until it arrives at a final output. You can use this code execution capability to build applications that benefit from code-based reasoning and that produce text output. For example, you could use code execution in an application that solves equations or processes text.
Code execution is available in both AI Studio and the Gemini API. In AI Studio, you can enable code execution in the right panel under Tools. The Gemini API provides code execution as a tool, similar to function calling. After you add code execution as a tool, the model decides when to use it.
The code execution environment includes the following libraries:
altair, chess, cv2, matplotlib, mpmath, numpy, pandas,
pdfminer, reportlab, seaborn, sklearn, statsmodels, striprtf,
sympy, and tabulate. You can't install your own libraries.
Get started with code execution
This section assumes that you've completed the setup and configuration steps shown in the quickstart.
Input/output (I/O)
Starting with Gemini 2.0 Flash, code execution supports file input and graph output. Using these new input and output capabilities, you can upload CSV and text files, ask questions about the files, and have Matplotlib graphs generated as part of the response.
I/O pricing
When using code execution I/O, you're charged for input tokens and output tokens:
Input tokens:
- User prompt
Output tokens:
- Code generated by the model
- Code execution output in the code environment
- Summary generated by the model
I/O details
When you're working with code execution I/O, be aware of the following technical details:
- The maximum runtime of the code environment is 30 seconds.
- If the code environment generates an error, the model may decide to regenerate the code output. This can happen up to 5 times.
- The maximum file input size is limited by the model token window. In AI Studio, using Gemini Flash 2.0, the maximum input file size is 1 million tokens (roughly 2MB for text files of the supported input types). If you upload a file that's too large, AI Studio won't let you send it.
| Single turn | Bidirectional (Multimodal Live API) | |
|---|---|---|
| Models supported | All Gemini 2.0 models | Only Flash experimental models |
| File input types supported | .png, .jpeg, .csv, .xml, .cpp, .java, .py, .js, .ts | .png, .jpeg, .csv, .xml, .cpp, .java, .py, .js, .ts |
| Plotting libraries supported | Matplotlib | Matplotlib |
| Multi-tool use | No | Yes |
Billing
There's no additional charge for enabling code execution from the Gemini API. You'll be billed at the current rate of input and output tokens based on the Gemini model you're using.
Here are a few other things to know about billing for code execution:
- You're only billed once for the input tokens you pass to the model, and you're billed for the final output tokens returned to you by the model.
- Tokens representing generated code are counted as output tokens. Generated code can include text and multimodal output like images.
- Code execution results are also counted as output tokens.
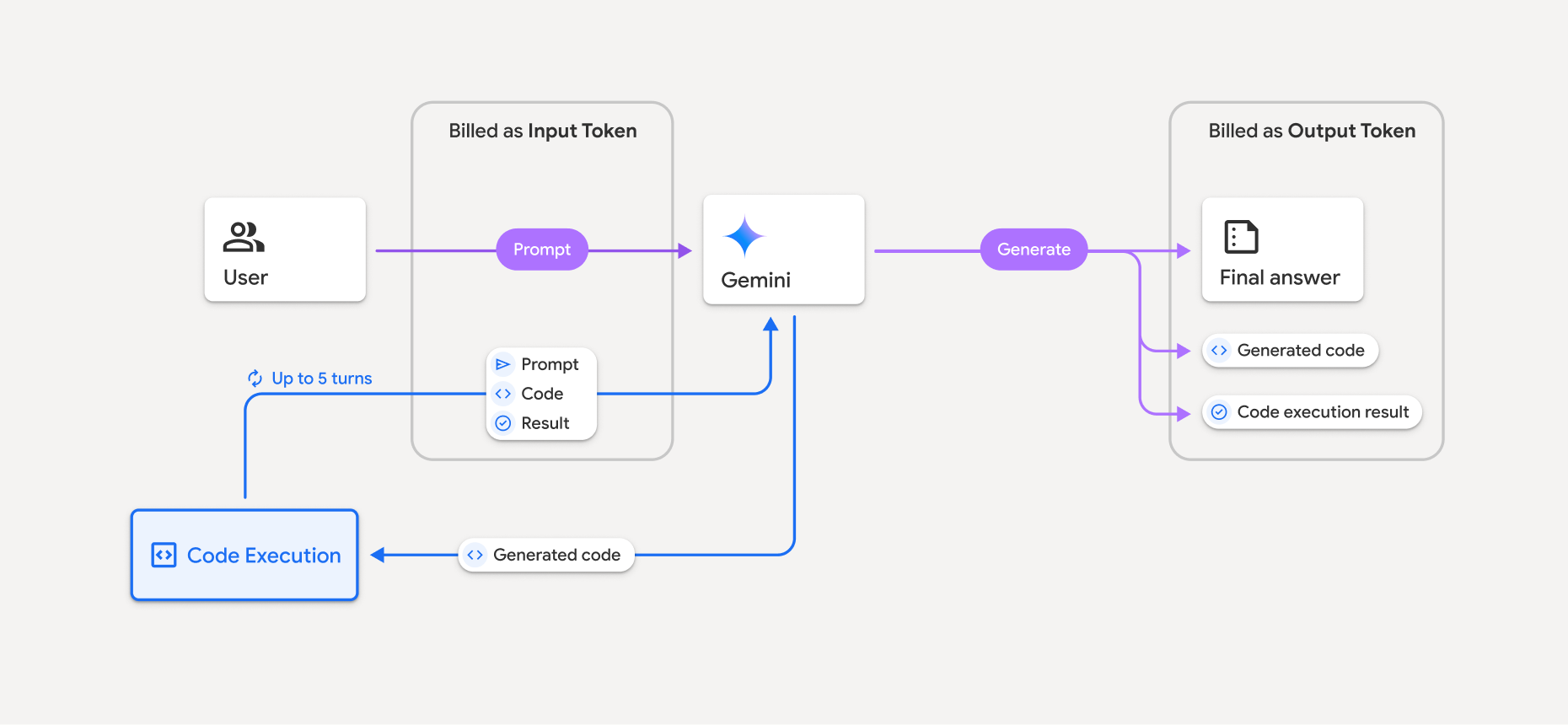
- You're billed at the current rate of input and output tokens based on the Gemini model you're using.
- If Gemini uses code execution when generating your response, the original prompt, the generated code, and the result of the executed code are labeled intermediate tokens and are billed as input tokens.
- Gemini then generates a summary and returns the generated code, the result of the executed code, and the final summary. These are billed as output tokens.
- The Gemini API includes an intermediate token count in the API response, so you know why you're getting additional input tokens beyond your initial prompt.
Limitations
- The model can only generate and execute code. It can't return other artifacts like media files.
- In some cases, enabling code execution can lead to regressions in other areas of model output (for example, writing a story).
- There is some variation in the ability of the different models to use code execution successfully.